
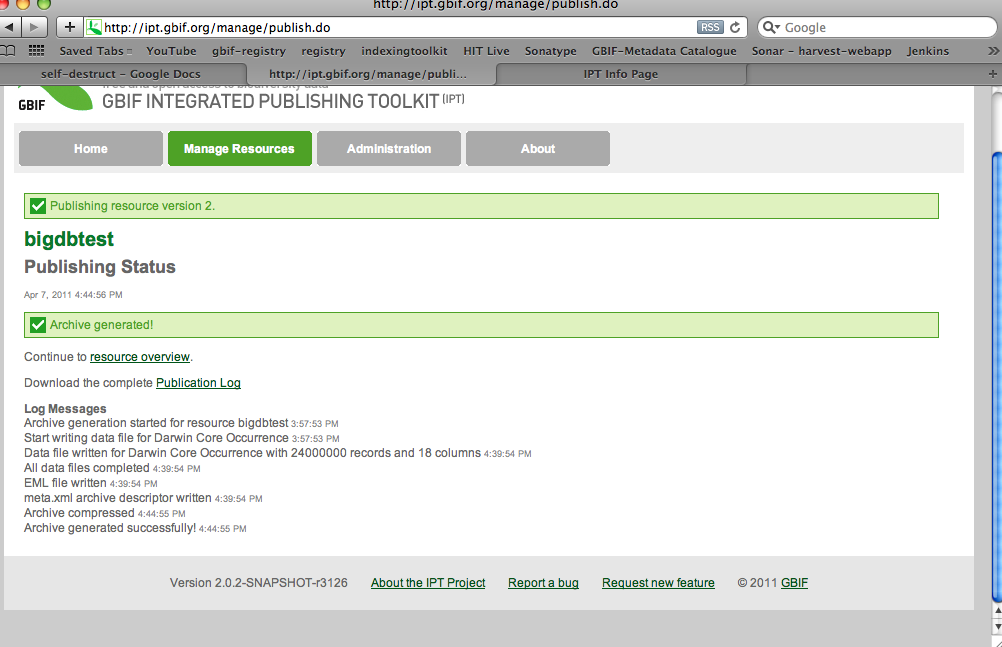
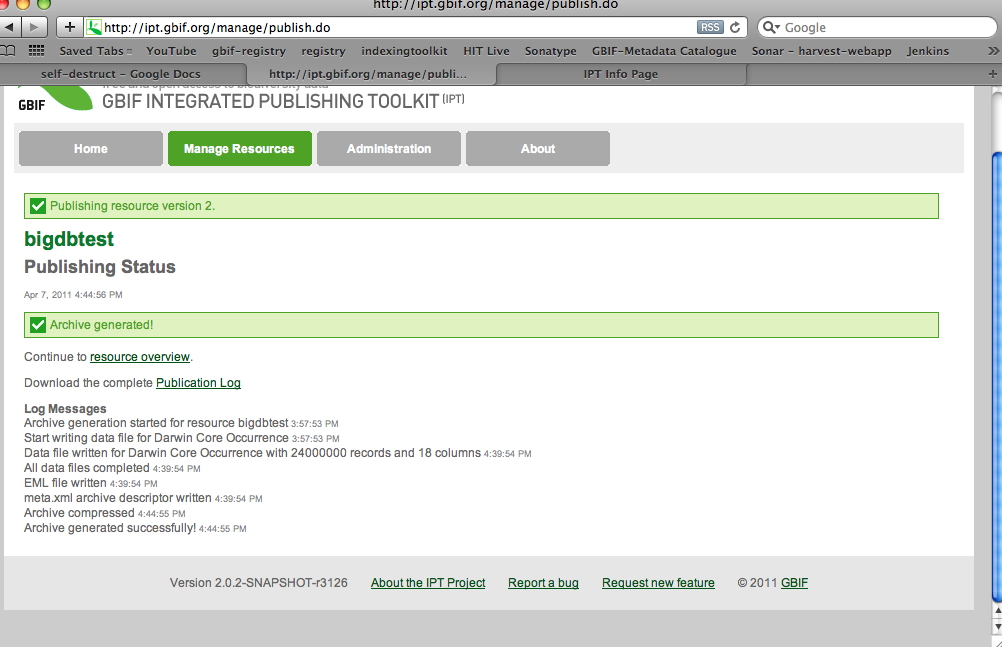
Dear IPT mailing list, This afternoon we conducted a little test to see whether the IPT2 can handle publishing a big dataset from a database. In the test we used a MySQL database, and successfully generated an archive with 24.000.000 records in about 50 minutes! This was run on a Tomcat server with 256MB memory. http://ipt.gbif.org/resource.do?r=bigdbtest Previously IPT1 had serious problems with such large datasets, but during IPT2 development special care was taken to be ensure that they could be handled gracefully. The way it is done now, is that the result sets from the database are streamed to the file system where they are written (about a 1000 records per result set) so there is no memory burden at all. This is one of the reasons why the IPT2 is not as feature rich as the IPT1 was. Best wishes, Kyle Braak Programmer Global Biodiversity Information Facility Secretariat Universitetsparken 15, DK-2100 Copenhagen, Denmark Tel: +45-35321479 Fax: +45-35321480 http://community.gbif.org/pg/profile/kbraak URL: http://www.gbif.org
{kind=link}

Nice! Congratulations on achieving such a critical goal. On Thu, Apr 7, 2011 at 8:41 AM, Kyle Braak (GBIF) <kbraak@gbif.org> wrote:
Dear IPT mailing list,
This afternoon we conducted a little test to see whether the IPT2 can handle publishing a big dataset from a database.
In the test we used a MySQL database, and successfully generated an archive with 24.000.000 records in about 50 minutes! This was run on a Tomcat server with 256MB memory.
http://ipt.gbif.org/resource.do?r=bigdbtest
Previously IPT1 had serious problems with such large datasets, but during IPT2 development special care was taken to be ensure that they could be handled gracefully. The way it is done now, is that the result sets from the database are streamed to the file system where they are written (about a 1000 records per result set) so there is no memory burden at all. This is one of the reasons why the IPT2 is not as feature rich as the IPT1 was.
Best wishes,
Kyle Braak Programmer Global Biodiversity Information Facility Secretariat Universitetsparken 15, DK-2100 Copenhagen, Denmark Tel: +45-35321479 Fax: +45-35321480 http://community.gbif.org/pg/profile/kbraak URL: http://www.gbif.org
_______________________________________________ IPT mailing list IPT@lists.gbif.org http://lists.gbif.org/mailman/listinfo/ipt
{kind=link}

Good news Perhaps it is possible that you publish more detailed info of this test as an example. Providers handle they local data in many different ways (excel, access, whatever ...), but MySQL is pretty commonly available in shared institutional servers. So having a good working sample of a well designed database schema (properly indexed) for providing massive DarwinCore data would be very useful as an example to follow (I mean an sql file with CREATE sentences for tables and indexes). Just an idea -- David García San León Herbario SANT Facultade de Farmacia - Laboratorio de Botánica Universidade de Santiago de Compostela 15782 - Galicia (Spain) http://www.usc.es/herbario Tel. +34 881815022 Fax +34 981594912

Hi David, This test was using a "select * from ... limit..." query from the MySQL DB that serves the GBIF data portal. The table queried was as below. It does not make too much sense to suggest schemas for use with the IPT as the IPT allows for mapping to the DwC terms from arbitrary schemas. However, if someone was designing a table for this purpose then creating a flat table with terms from the DwC would be a good start. In essence the GBIF portal looks similar to that structure, and currently holds 270 million + records. If the DB were being used for multiple collections and normally queried on a single collection at a time, it would make sense to do range partitioning (http://dev.mysql.com/doc/refman/5.1/en/partitioning-range.html ) although you would have to be into many millions of records, or on poor hardware to really notice the benefits. If your queries are spanning all collections, then you would not want to do that either, as performance would degrade; you may consider a different partitioning strategy though if your query patterns allow it. The most important thing I would recommend with databases is to use the smallest types possible (e.g. UNSIGNED SMALL INT instead of INT) - the difference in performance is astronomical as the DB grows, and something we learnt with the GBIF Portal as it grew. Hope this helps, Tim CREATE TABLE `raw_occurrence_record` ( `id` int(11) NOT NULL auto_increment, `data_provider_id` smallint(6) default NULL, `data_resource_id` smallint(6) default NULL, `resource_access_point_id` smallint(6) default NULL, `institution_code` varchar(255) default NULL, `collection_code` varchar(255) default NULL, `catalogue_number` varchar(255) default NULL, `scientific_name` varchar(255) default NULL, `author` varchar(255) default NULL, `rank` varchar(50) default NULL, `kingdom` varchar(150) default NULL, `phylum` varchar(150) default NULL, `class` varchar(250) default NULL, `order_rank` varchar(50) default NULL, `family` varchar(250) default NULL, `genus` varchar(150) default NULL, `species` varchar(150) default NULL, `subspecies` varchar(150) default NULL, `latitude` varchar(50) default NULL, `longitude` varchar(50) default NULL, `lat_long_precision` varchar(50) default NULL, `max_altitude` varchar(50) default NULL, `min_altitude` varchar(50) default NULL, `altitude_precision` varchar(50) default NULL, `min_depth` varchar(50) default NULL, `max_depth` varchar(50) default NULL, `depth_precision` varchar(50) default NULL, `continent_ocean` varchar(100) default NULL, `country` varchar(100) default NULL, `state_province` varchar(100) default NULL, `county` varchar(100) default NULL, `collector_name` varchar(255) default NULL, `locality` text, `year` varchar(50) default NULL, `month` varchar(50) default NULL, `day` varchar(50) default NULL, `basis_of_record` varchar(100) default NULL, `identifier_name` varchar(255) default NULL, `identification_date` datetime default NULL, `unit_qualifier` varchar(255) default NULL, `created` timestamp NULL default NULL, `modified` timestamp NULL default NULL, `deleted` timestamp NULL default NULL, PRIMARY KEY (`id`), KEY `created` (`created`,`modified`), KEY `data_resource_id` (`data_resource_id`,`catalogue_number`), KEY `resource_access_point_id` (`resource_access_point_id`,`id`) ) ENGINE=MyISAM AUTO_INCREMENT=329086455 DEFAULT CHARSET=utf8 On Apr 9, 2011, at 1:47 PM, Herbario SANT wrote:
Good news
Perhaps it is possible that you publish more detailed info of this test as an example. Providers handle they local data in many different ways (excel, access, whatever ...), but MySQL is pretty commonly available in shared institutional servers. So having a good working sample of a well designed database schema (properly indexed) for providing massive DarwinCore data would be very useful as an example to follow (I mean an sql file with CREATE sentences for tables and indexes). Just an idea
-- David García San León Herbario SANT Facultade de Farmacia - Laboratorio de Botánica Universidade de Santiago de Compostela 15782 - Galicia (Spain) http://www.usc.es/herbario Tel. +34 881815022 Fax +34 981594912
_______________________________________________ IPT mailing list IPT@lists.gbif.org http://lists.gbif.org/mailman/listinfo/ipt
participants (4)
-
 Herbario SANT
Herbario SANT -
 John Wieczorek
John Wieczorek -
 Kyle Braak (GBIF)
Kyle Braak (GBIF) -
 Tim Robertson (GBIF)
Tim Robertson (GBIF)