use of extensions; how can duplication of rows be avoided?

Dear all, I have a general question on Darwin Core and the use of Darwin Core extensions. E.g. I want to use the Occurrence Core and Simple Images with a mysql database. Problem: Only a few of my occurrences have images. The Darwin Core Archive creates a large images file with all occurrence IDs and only a few have also Image urls. But I did expect a file with the image urls only (so much shorter) and all occurrences (with or without image) in the occurrences file. The same problem appears for the identification extension the other way round (duplication of occurrence rows for multiple identifications) and every other extension I've tested... But I am a bit confused how this can be done with only one big sql query (with some left joins). Do I have to use multiple resources to use multiple sql queries? Or is this a problem/bug of IPT? Best, Gabi

Hi Gabi, In *typical* use there would be 1 SQL statement for the core, and then one SQL statement per extension. There are occasions that you would break this though. If I were setting up an IPT on MySQL I would use views in the database, and manage those with the database database schema itself. So something along the lines of: CREATE VIEW view_ipt_occurrence AS SELECT id AS id, id AS occurrenceID, name AS scientificName … FROM specimen; CREATE VIEW view_ipt_image AS SELECT s.id AS id, s.id AS SELECT occurrenceID, i.image AS imageURL … FROM image i JOIN specimen s ON i.specimen_id=s.id; Then in the IPT on the occurrence mapping I would simply use this knowing it will auto map since the views use DwC terms as column aliases: SELECT * FROM view_ipt_occurrence; SELECT * FROM view_ipt_image; Does that help at all? If you send your DB schema, we will be happy to help out with SQL mappings. Thanks, Tim On Oct 23, 2013, at 1:39 PM, Dröge, Gabriele wrote:
Dear all,
I have a general question on Darwin Core and the use of Darwin Core extensions.
E.g. I want to use the Occurrence Core and Simple Images with a mysql database.
Problem: Only a few of my occurrences have images. The Darwin Core Archive creates a large images file with all occurrence IDs and only a few have also Image urls.
But I did expect a file with the image urls only (so much shorter) and all occurrences (with or without image) in the occurrences file.
The same problem appears for the identification extension the other way round (duplication of occurrence rows for multiple identifications) and every other extension I’ve tested…
But I am a bit confused how this can be done with only one big sql query (with some left joins). Do I have to use multiple resources to use multiple sql queries? Or is this a problem/bug of IPT?
Best, Gabi _______________________________________________ IPT mailing list IPT@lists.gbif.org http://lists.gbif.org/mailman/listinfo/ipt
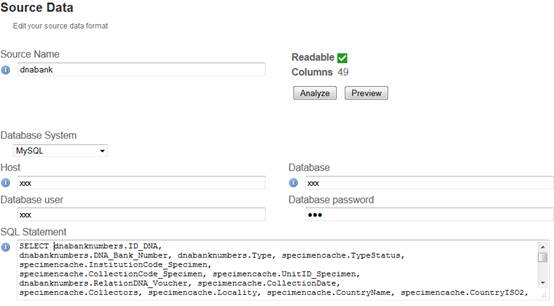
Hi Tim, Ok, but I am already using such views. How can I use multiple sqls in IPT? E.g. those two you suggested. Do you want me to put them all together in the same Source Data SQL Statement field? Best, Gabi [cid:image001.jpg@01CECFFC.F3F793C0] Von: Tim Robertson [GBIF] [mailto:trobertson@gbif.org] Gesendet: Mittwoch, 23. Oktober 2013 14:01 An: Dröge, Gabriele Cc: ipt@lists.gbif.org Betreff: Re: [IPT] use of extensions; how can duplication of rows be avoided? Hi Gabi, In *typical* use there would be 1 SQL statement for the core, and then one SQL statement per extension. There are occasions that you would break this though. If I were setting up an IPT on MySQL I would use views in the database, and manage those with the database database schema itself. So something along the lines of: CREATE VIEW view_ipt_occurrence AS SELECT id AS id, id AS occurrenceID, name AS scientificName ... FROM specimen; CREATE VIEW view_ipt_image AS SELECT s.id AS id, s.id AS SELECT occurrenceID, i.image AS imageURL ... FROM image i JOIN specimen s ON i.specimen_id=s.id; Then in the IPT on the occurrence mapping I would simply use this knowing it will auto map since the views use DwC terms as column aliases: SELECT * FROM view_ipt_occurrence; SELECT * FROM view_ipt_image; Does that help at all? If you send your DB schema, we will be happy to help out with SQL mappings. Thanks, Tim On Oct 23, 2013, at 1:39 PM, Dröge, Gabriele wrote: Dear all, I have a general question on Darwin Core and the use of Darwin Core extensions. E.g. I want to use the Occurrence Core and Simple Images with a mysql database. Problem: Only a few of my occurrences have images. The Darwin Core Archive creates a large images file with all occurrence IDs and only a few have also Image urls. But I did expect a file with the image urls only (so much shorter) and all occurrences (with or without image) in the occurrences file. The same problem appears for the identification extension the other way round (duplication of occurrence rows for multiple identifications) and every other extension I've tested... But I am a bit confused how this can be done with only one big sql query (with some left joins). Do I have to use multiple resources to use multiple sql queries? Or is this a problem/bug of IPT? Best, Gabi _______________________________________________ IPT mailing list IPT@lists.gbif.org<mailto:IPT@lists.gbif.org> http://lists.gbif.org/mailman/listinfo/ipt
{kind=link}
Hi Gabe, You create 2 sources (both will point to the same database in your instance) and each will have a different SQL statement. It is probably not noticed, but with an IPT you can actually do things like connecting to a postgres database for specimens, and connecting to a mysql database for images provided there are shared unique identifiers in use that effectively do cross database joins. That is pretty advanced usage, but is likely to crop up. Similarly you can upload a CSV file and mix that in with a database connection. Cheers, Tim On Oct 23, 2013, at 2:34 PM, Dröge, Gabriele wrote:
Hi Tim,
Ok, but I am already using such views. How can I use multiple sqls in IPT? E.g. those two you suggested. Do you want me to put them all together in the same Source Data SQL Statement field?
Best, Gabi
<image001.jpg>
Von: Tim Robertson [GBIF] [mailto:trobertson@gbif.org] Gesendet: Mittwoch, 23. Oktober 2013 14:01 An: Dröge, Gabriele Cc: ipt@lists.gbif.org Betreff: Re: [IPT] use of extensions; how can duplication of rows be avoided?
Hi Gabi,
In *typical* use there would be 1 SQL statement for the core, and then one SQL statement per extension. There are occasions that you would break this though.
If I were setting up an IPT on MySQL I would use views in the database, and manage those with the database database schema itself. So something along the lines of:
CREATE VIEW view_ipt_occurrence AS SELECT id AS id, id AS occurrenceID, name AS scientificName … FROM specimen;
CREATE VIEW view_ipt_image AS SELECT s.id AS id, s.id AS SELECT occurrenceID, i.image AS imageURL … FROM image i JOIN specimen s ON i.specimen_id=s.id;
Then in the IPT on the occurrence mapping I would simply use this knowing it will auto map since the views use DwC terms as column aliases: SELECT * FROM view_ipt_occurrence; SELECT * FROM view_ipt_image;
Does that help at all?
If you send your DB schema, we will be happy to help out with SQL mappings.
Thanks, Tim
On Oct 23, 2013, at 1:39 PM, Dröge, Gabriele wrote:
Dear all,
I have a general question on Darwin Core and the use of Darwin Core extensions.
E.g. I want to use the Occurrence Core and Simple Images with a mysql database.
Problem: Only a few of my occurrences have images. The Darwin Core Archive creates a large images file with all occurrence IDs and only a few have also Image urls.
But I did expect a file with the image urls only (so much shorter) and all occurrences (with or without image) in the occurrences file.
The same problem appears for the identification extension the other way round (duplication of occurrence rows for multiple identifications) and every other extension I’ve tested…
But I am a bit confused how this can be done with only one big sql query (with some left joins). Do I have to use multiple resources to use multiple sql queries? Or is this a problem/bug of IPT?
Best, Gabi _______________________________________________ IPT mailing list IPT@lists.gbif.org http://lists.gbif.org/mailman/listinfo/ipt
Hi Tim, ok thanks. This what I was thinking but I wanted to be sure. Will try this. Best, Gabi Von: Tim Robertson [GBIF] [mailto:trobertson@gbif.org] Gesendet: Mittwoch, 23. Oktober 2013 14:41 An: Dröge, Gabriele Cc: ipt@lists.gbif.org Betreff: Re: [IPT] use of extensions; how can duplication of rows be avoided? Hi Gabe, You create 2 sources (both will point to the same database in your instance) and each will have a different SQL statement. It is probably not noticed, but with an IPT you can actually do things like connecting to a postgres database for specimens, and connecting to a mysql database for images provided there are shared unique identifiers in use that effectively do cross database joins. That is pretty advanced usage, but is likely to crop up. Similarly you can upload a CSV file and mix that in with a database connection. Cheers, Tim On Oct 23, 2013, at 2:34 PM, Dröge, Gabriele wrote: Hi Tim, Ok, but I am already using such views. How can I use multiple sqls in IPT? E.g. those two you suggested. Do you want me to put them all together in the same Source Data SQL Statement field? Best, Gabi <image001.jpg> Von: Tim Robertson [GBIF] [mailto:trobertson@gbif.org] Gesendet: Mittwoch, 23. Oktober 2013 14:01 An: Dröge, Gabriele Cc: ipt@lists.gbif.org<mailto:ipt@lists.gbif.org> Betreff: Re: [IPT] use of extensions; how can duplication of rows be avoided? Hi Gabi, In *typical* use there would be 1 SQL statement for the core, and then one SQL statement per extension. There are occasions that you would break this though. If I were setting up an IPT on MySQL I would use views in the database, and manage those with the database database schema itself. So something along the lines of: CREATE VIEW view_ipt_occurrence AS SELECT id AS id, id AS occurrenceID, name AS scientificName ... FROM specimen; CREATE VIEW view_ipt_image AS SELECT s.id AS id, s.id AS SELECT occurrenceID, i.image AS imageURL ... FROM image i JOIN specimen s ON i.specimen_id=s.id; Then in the IPT on the occurrence mapping I would simply use this knowing it will auto map since the views use DwC terms as column aliases: SELECT * FROM view_ipt_occurrence; SELECT * FROM view_ipt_image; Does that help at all? If you send your DB schema, we will be happy to help out with SQL mappings. Thanks, Tim On Oct 23, 2013, at 1:39 PM, Dröge, Gabriele wrote: Dear all, I have a general question on Darwin Core and the use of Darwin Core extensions. E.g. I want to use the Occurrence Core and Simple Images with a mysql database. Problem: Only a few of my occurrences have images. The Darwin Core Archive creates a large images file with all occurrence IDs and only a few have also Image urls. But I did expect a file with the image urls only (so much shorter) and all occurrences (with or without image) in the occurrences file. The same problem appears for the identification extension the other way round (duplication of occurrence rows for multiple identifications) and every other extension I've tested... But I am a bit confused how this can be done with only one big sql query (with some left joins). Do I have to use multiple resources to use multiple sql queries? Or is this a problem/bug of IPT? Best, Gabi _______________________________________________ IPT mailing list IPT@lists.gbif.org<mailto:IPT@lists.gbif.org> http://lists.gbif.org/mailman/listinfo/ipt

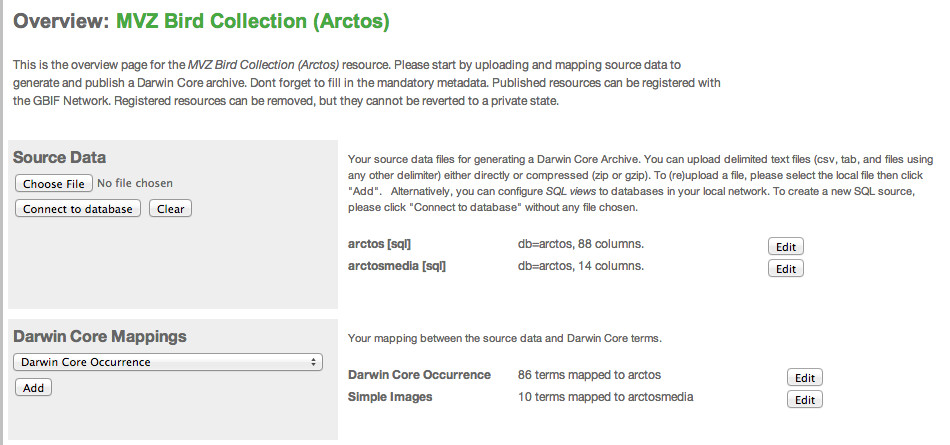
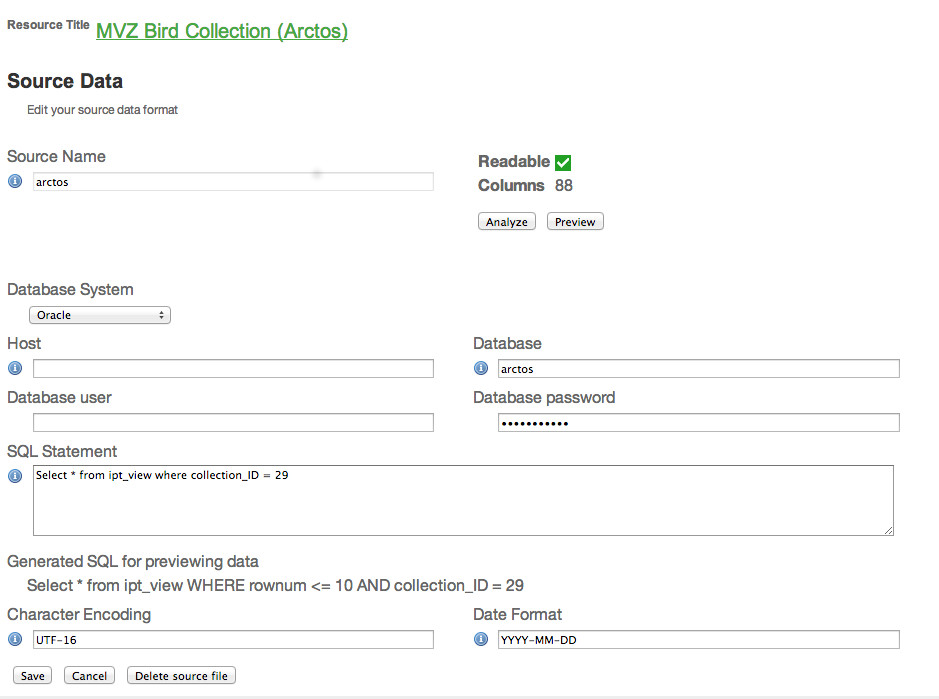
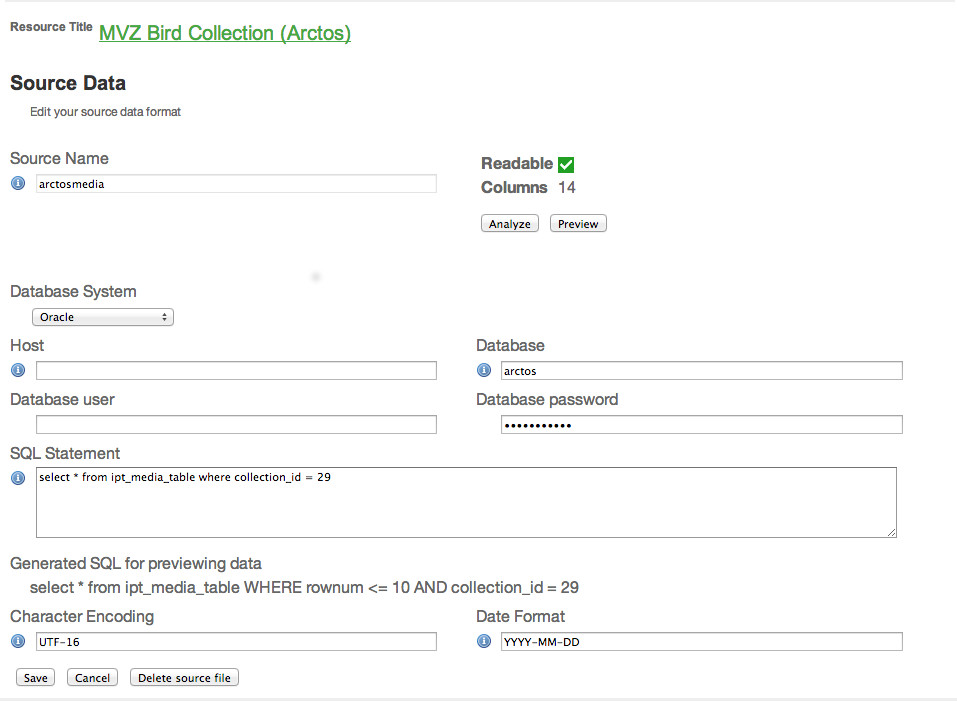
If it is helpful, I've attached three screen shots from the VertNet IPT. The first shows what the Manage Resource page looks like with two data sources and two mappings. The second shot shows the Edit Source page for the DwC Occurrence data and the third shot shows the Edit Source page for the Simple Images data. Laura Russell VertNet Programmer VertNet KU Biodiversity Institute 1345 Jayhawk Blvd. Dyche Hall, Room 606 Lawrence, KS 66045 Phone: +01 785 864-4681 Fax: +01 785 864-5335 email: larussell@vertnet.org email: larussell@ku.edu Skype: laura.anne.russell Gchat: larussell@vertnet.org url: www.vertnet.org From: "Dröge, Gabriele" <g.droege@BGBM.ORG> Date: Wednesday, October 23, 2013 8:04 AM To: "Tim Robertson [GBIF]" <trobertson@gbif.org> Cc: "ipt@lists.gbif.org" <ipt@lists.gbif.org> Subject: Re: [IPT] use of extensions; how can duplication of rows be avoided? Hi Tim, ok thanks. This what I was thinking but I wanted to be sure. Will try this. Best, Gabi Von: Tim Robertson [GBIF] [mailto:trobertson@gbif.org] Gesendet: Mittwoch, 23. Oktober 2013 14:41 An: Dröge, Gabriele Cc: ipt@lists.gbif.org Betreff: Re: [IPT] use of extensions; how can duplication of rows be avoided? Hi Gabe, You create 2 sources (both will point to the same database in your instance) and each will have a different SQL statement. It is probably not noticed, but with an IPT you can actually do things like connecting to a postgres database for specimens, and connecting to a mysql database for images provided there are shared unique identifiers in use that effectively do cross database joins. That is pretty advanced usage, but is likely to crop up. Similarly you can upload a CSV file and mix that in with a database connection. Cheers, Tim On Oct 23, 2013, at 2:34 PM, Dröge, Gabriele wrote: Hi Tim, Ok, but I am already using such views. How can I use multiple sqls in IPT? E.g. those two you suggested. Do you want me to put them all together in the same Source Data SQL Statement field? Best, Gabi <image001.jpg> Von: Tim Robertson [GBIF] [mailto:trobertson@gbif.org] Gesendet: Mittwoch, 23. Oktober 2013 14:01 An: Dröge, Gabriele Cc: ipt@lists.gbif.org Betreff: Re: [IPT] use of extensions; how can duplication of rows be avoided? Hi Gabi, In *typical* use there would be 1 SQL statement for the core, and then one SQL statement per extension. There are occasions that you would break this though. If I were setting up an IPT on MySQL I would use views in the database, and manage those with the database database schema itself. So something along the lines of: CREATE VIEW view_ipt_occurrence AS SELECT id AS id, id AS occurrenceID, name AS scientificName FROM specimen; CREATE VIEW view_ipt_image AS SELECT s.id AS id, s.id AS SELECT occurrenceID, i.image AS imageURL FROM image i JOIN specimen s ON i.specimen_id=s.id; Then in the IPT on the occurrence mapping I would simply use this knowing it will auto map since the views use DwC terms as column aliases: SELECT * FROM view_ipt_occurrence; SELECT * FROM view_ipt_image; Does that help at all? If you send your DB schema, we will be happy to help out with SQL mappings. Thanks, Tim On Oct 23, 2013, at 1:39 PM, Dröge, Gabriele wrote: Dear all, I have a general question on Darwin Core and the use of Darwin Core extensions. E.g. I want to use the Occurrence Core and Simple Images with a mysql database. Problem: Only a few of my occurrences have images. The Darwin Core Archive creates a large images file with all occurrence IDs and only a few have also Image urls. But I did expect a file with the image urls only (so much shorter) and all occurrences (with or without image) in the occurrences file. The same problem appears for the identification extension the other way round (duplication of occurrence rows for multiple identifications) and every other extension I¹ve tested But I am a bit confused how this can be done with only one big sql query (with some left joins). Do I have to use multiple resources to use multiple sql queries? Or is this a problem/bug of IPT? Best, Gabi _______________________________________________ IPT mailing list IPT@lists.gbif.org http://lists.gbif.org/mailman/listinfo/ipt _______________________________________________ IPT mailing list IPT@lists.gbif.org http://lists.gbif.org/mailman/listinfo/ipt
{kind=link}
{kind=link}
{kind=link}

Happy new year everybody. I have two questions here. 1. I am searching for DarwinCore element "verbatim_scientific_name" is this available somewhere? 2. I have a need for a non DarwinCore field namely "WaterBodyType" with values such as (RIVER|LAKE|ESTUARY|SEA|...) I have looked but it does not seem to exist in DarwinCore. WaterBody does exist but this refers to the name of the water body such as "Nile river" or "Ganges river" or just "Amazon" . I want something that just specifies the type. Would it be possible to define such a field and add it to the mapping interface? Thanks in advance for any info. Michel K.
participants (4)
-
 "Dröge, Gabriele"
"Dröge, Gabriele" -
 Laura Russell
Laura Russell -
 Michel Kapel
Michel Kapel -
 Tim Robertson [GBIF]
Tim Robertson [GBIF]