Re: [IPT] GBIF Integrated Publishing Toolkit

Dear Jonas, Thank you for your questions. Answers given inline:
Dear Tim
Thanks for the information, and the great work on the IPT. I think it will be a good move, just seen from my perspective, to concentrate on the core functionality for better performance.
Thank you for this feedback - this is important to help steer the IPT process.
After having done some promotion and held some training and installation sessions of the IPT under the GBIF - NordGen evaluation project I see that the general interest in the genebank documentation community is quite strong and the installation and configuration is very user-friendly. We just this week had a workshop in Estonia introducing the IPT and the GBIF network to people from genebanks in Estonia, Latvia and Lithuania and the response was very good.
To be able to make the most out of these training sessions, there will be a few more during the remainder of this year, I have a couple of questions about the coming version:
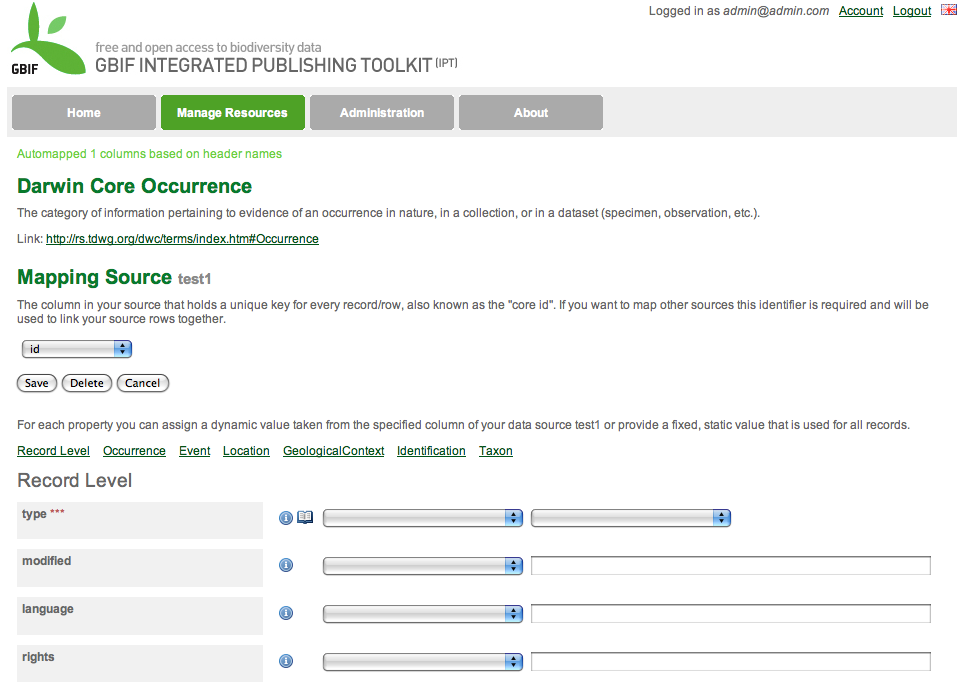
if the GUI for mapping imported dataset fields to the DwC / DwC extension fields will be significantly different?
It will be slightly different, but familiar enough for people who understand the older version to pick it up easily. We received feedback during the IPT experts training event last year, and have implemented their recommendations. In short, the terms are simply provided in a long list. I attach a screenshot (dwc-mapping.png) showing the mapping page for occurrences. Please remember that we will initiate a testing phase in October, and there will be the ability to comment on this and have it revised if there are problems.
if the mapping through SQL / direct database connection will work significantly different?
No changes here. You create the SQL statement and then do a mapping the same, regardless of whether it is a SQL source or text file.
if it will be possible to host multiple resources registered under different GBIF nodes on the same IPT webapp or if all resources on one IPT webapp must be under the same GBIF node?
The revised version will handle this: The IPT instance is registered with the Institution/Organisation/Node to which it is associated. The ADMIN user can then associate further Institution/Organisation/ Nodes from which data MANAGERs can choose when registering a data RESOURCE. Therefore the following could be handled: - ADMIN in Node1 installs the IPT - ADMIN enables Node2 and Institution3 as available entities for MANAGERs to use - ADMIN creates accounts for MANAGERs - MANAGERs can log in and create resources - when a MANAGER creates a resource they see a choice of Node1, Node2 or Institution3 to associate the resource with In addition to this, the ADMIN can provide an alias to each Organisation/Node/Institution, so that MANAGERs see something familiar. For example the GBIF Registry might have "The Botanical holdings of the Harvard Herbarium Museum" but internally the ADMIN and MANAGERs all call this "HUH". The ADMIN will be able to declare this and MANAGERs will simply see "HUH" in the choice of Institutions to associate the resource with. I hope this helps, and thanks again for the feedback, Tim
Best regards
Jonas Nordling, NordGen From: trobertson@gbif.org To: jonas.nordling@nordgen.org Sent: Mon, 13 Sep 2010 16:10:36 +0200 Subject: GBIF Integrated Publishing Toolkit
[FOR INFORMATION]
Dear Node Managers and Data Publishers,
The objective of this communication is to update you on the current situation of the GBIF Integrated Publishing Toolkit (IPT). The IPT is a tool providing publishing capabilities for primary biodiversity occurrence data, taxonomic checklists and the associated metadata for these resource types.
Since its first introduction in March 2009, the IPT has been used with some success by a limited number of users to publish primary biodiversity data into the GBIF network, along with descriptive metadata at the dataset level.
The GBIF Secretariat (GBIFS) has solicited and received a vast amount of feedback during the first year of the IPT use, and would like to thank all those who provided this. The feedback received overwhelmingly confirms that the concept of the IPT is sound. However, feedback has also made it clear that it is over-specified for the majority of user needs, is not yet sufficiently robust, is too slow in operation, and (due to the excessive functionality) has high server requirements creating a barrier for many to adopt and use it. In addition, the feedback has made it clear that our communications surrounding the status of the IPT releases have been too infrequent and unclear concerning which release candidate we were offering and what functionalities this release candidate would include or not include, as per user needs/expectations.
Based upon the extensive feedback GBIFS has revised our planned development roadmap for the IPT and are currently performing a major refactoring effort to: • Reduce the server requirements significantly • Increase the data import performance by removing the embedded database • Remove the dependency on heavy libraries and tools such as Geoserver • Remove all data interfaces that are not necessary for data publication through GBIF • Improve the robustness of the tool
When complete, the refactored IPT will offer through an intuitive interface: • Authoring of metadata according to the GBIF metadata profile • Import and mapping of checklist and occurrence data either from file upload or by connection of a database • Registration to and publication onto the GBIF network • Importing and mapping of data to the DarwinCore, and DarwinCore extensions • Output formats of EML (2.1.0) metadata and DarwinCore Archive • Improved customisation options for the “About this IPT” • Improved GBIF Registry integration • Improved DarwinCore extension and vocabulary organization • Improved management of the organisations to which the IPT and resources are related, to enable co-hosting capabilities • Enhanced dataset metadata authoring
Whilst this is a reduction in existing functionality this has been deemed necessary to ensure the IPT is meeting the core requirements as expressed by the user community. The following features will be removed and only reintroduced if necessary through consultation with the IPT community: • TAPIR interface • TCS output format • Search and browse web interface • OGC web services
All IPT development efforts are now focused on this revised roadmap, and it is anticipated that early testing of the new codebase will commence in October 2010 with the involvement of willing Nodes. The release of a fully stable IPT is targeted for the end of 2010. However, this will only occur if the testing community is satisfied that the product is ‘release-ready’ together with the required user manual and technical documentation. Should that not be the case, as it may take more time to implement and test the improvements outlined above, you will be informed as soon as possible.
Further developments of the IPT beyond this release will only be implemented after a further scoping with the GBIF community. An area for further IPT discussion will be set up on the GBIF community website (http://community.gbif.org)
If you have any questions or would like to know more about the GBIF IPT and/or revised process, feel free to contact:
Tim Robertson GBIF Information Systems Architect trobertson@gbif.org
With best regards,
Tim Robertson GBIF Secretariat
{kind=link}
participants (1)
-
 Tim Robertson (GBIF)
Tim Robertson (GBIF)