
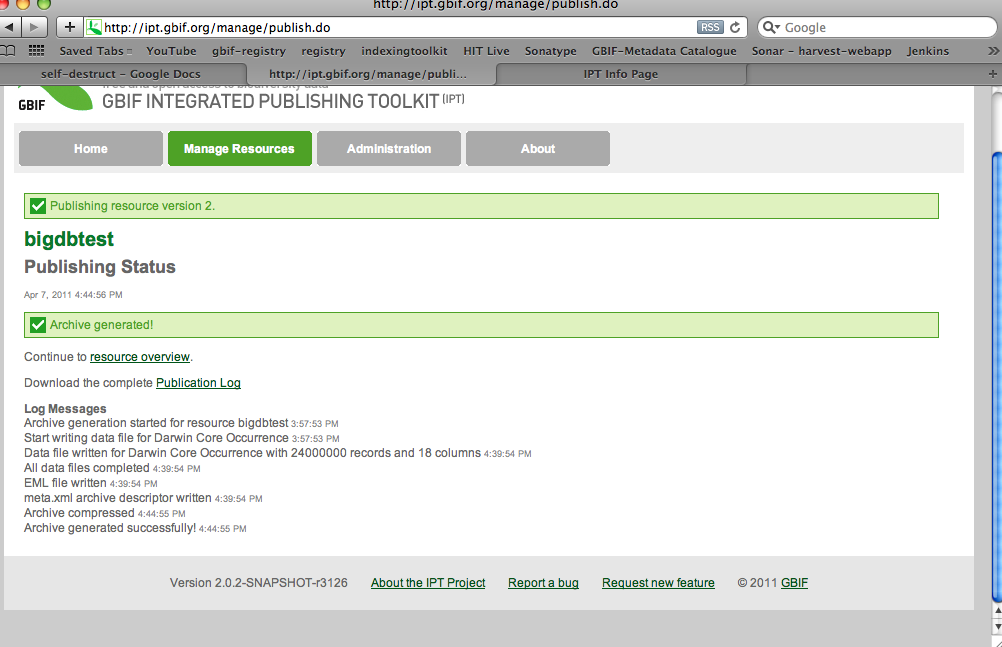
Dear IPT mailing list, This afternoon we conducted a little test to see whether the IPT2 can handle publishing a big dataset from a database. In the test we used a MySQL database, and successfully generated an archive with 24.000.000 records in about 50 minutes! This was run on a Tomcat server with 256MB memory. http://ipt.gbif.org/resource.do?r=bigdbtest Previously IPT1 had serious problems with such large datasets, but during IPT2 development special care was taken to be ensure that they could be handled gracefully. The way it is done now, is that the result sets from the database are streamed to the file system where they are written (about a 1000 records per result set) so there is no memory burden at all. This is one of the reasons why the IPT2 is not as feature rich as the IPT1 was. Best wishes, Kyle Braak Programmer Global Biodiversity Information Facility Secretariat Universitetsparken 15, DK-2100 Copenhagen, Denmark Tel: +45-35321479 Fax: +45-35321480 http://community.gbif.org/pg/profile/kbraak URL: http://www.gbif.org
{kind=link}